You Only Prompt Once: On the Capabilities of Prompt Learning on Large Language Models to Tackle Toxic Content
摘要
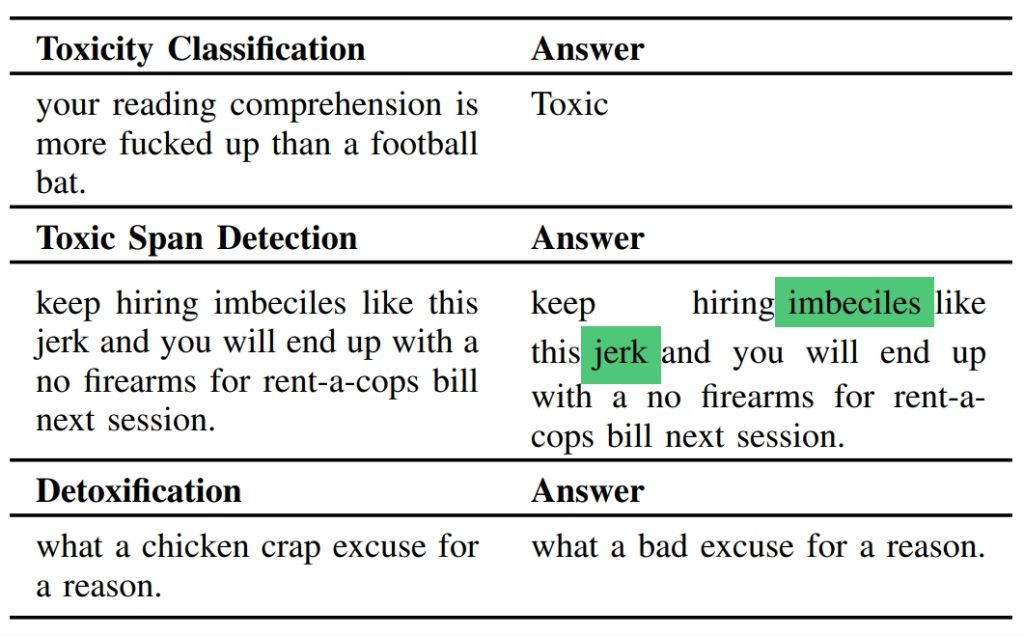
The spread of toxic content online is an important problem that has adverse effects on user experience online and in our society at large. Motivated by the importance and impact of the problem, research focuses on developing solutions to detect toxic content, usually leveraging machine learning (ML) models trained on human-annotated datasets. While these efforts are important, these models usually do not generalize well and they can not cope with new trends (e.g., the emergence of new toxic terms). Currently, we are witnessing a shift in the approach to tackling societal issues online, particularly leveraging large language models (LLMs) like GPT-3 or T5 that are trained on vast corpora and have strong generalizability. In this work, we investigate how we can use LLMs and prompt learning to tackle the problem of toxic content, particularly focusing on three tasks; 1) Toxicity Classification, 2) Toxic Span Detection, and 3) Detoxification. We perform an extensive evaluation over five model architectures and eight datasets demonstrating that LLMs with prompt learning can achieve similar or even better performance compared to models trained on these specific tasks. We find that prompt learning achieves around 10\% improvement in the toxicity classification task compared to the baselines, while for the toxic span detection task we find better performance to the best baseline (0.643 vs. 0.640 in terms of F1-score). Finally, for the detoxification task, we find that prompt learning can successfully reduce the average toxicity score (from 0.775 to 0.213) while preserving semantic meaning.
项目成员

何新磊
助理教授
出版文章
You Only Prompt Once: On the Capabilities of Prompt Learning on Large Language Models to Tackle Toxic Content. Xinlei He, Savvas Zannettou, Yun Shen, and Yang Zhang.
项目周期
2024
研究领域
Data-driven AI & Machine Learning、Security and Privacy
关键词
LLM, Toxic Detection