ML-Doctor: Holistic Risk Assessment of Inference Attacks Against Machine Learning Models
摘要
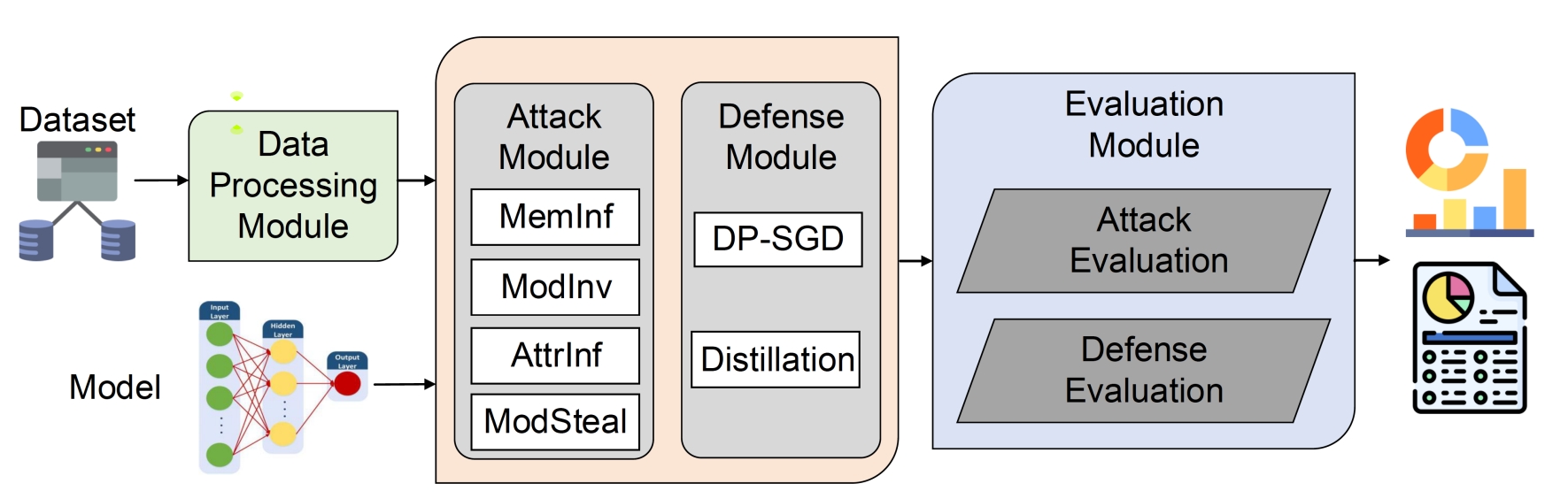
Inference attacks against Machine Learning (ML) models allow adversaries to learn sensitive information about training data, model parameters, etc. While researchers have studied, in depth, several kinds of attacks, they have done so in isolation. As a result, we lack a comprehensive picture of the risks caused by the attacks, e.g., the different scenarios they can be applied to, the common factors that influence their performance, the relationship among them, or the effectiveness of possible defenses. In this paper, we fill this gap by presenting a first-of-its-kind holistic risk assessment of different inference attacks against machine learning models. We concentrate on four attacks -- namely, membership inference, model inversion, attribute inference, and model stealing -- and establish a threat model taxonomy.
Our extensive experimental evaluation, run on five model architectures and four image datasets, shows that the complexity of the training dataset plays an important role with respect to the attack's performance, while the effectiveness of model stealing and membership inference attacks are negatively correlated. We also show that defenses like DP-SGD and Knowledge Distillation can only mitigate some of the inference attacks. Our analysis relies on a modular re-usable software, ML-Doctor, which enables ML model owners to assess the risks of deploying their models, and equally serves as a benchmark tool for researchers and practitioners.
项目成员

何新磊
助理教授
出版文章
ML-Doctor: Holistic Risk Assessment of Inference Attacks Against Machine Learning Models. Yugeng Liu, Rui Wen, Xinlei He, Ahmed Salem, Zhikun Zhang, Michael Backes, Emiliano De Cristofaro, Mario Fritz, and Yang Zhang.
项目周期
2021
研究领域
Data-driven AI & Machine Learning、Security and Privacy
关键词
Benchmark, Inference Attack