The Knowledge Base Group
Abstract
The KB (knowledge base) group conducts research related to automatic knowledge extraction, refinement and knowledge-based question answering, from algorithm design to application development.
Prof. Chen’s team collaborated with Upstage in building the product domain knowledge base using both the subjective and objective knowledge buried in the E-commercial websites. Such knowledge can be used to facilitate the shopping needs of consumers, such as searching or question answering (QA). Recently, although some open-domain knowledge bases construction methods have been proposed, such techniques for entity-related knowledge extraction often require huge amount of data. Prof. Chen’s team has studied human-in-the-loop methods to combine the subjective information and objective information to build domain specific knowledge base with less annotation cost.
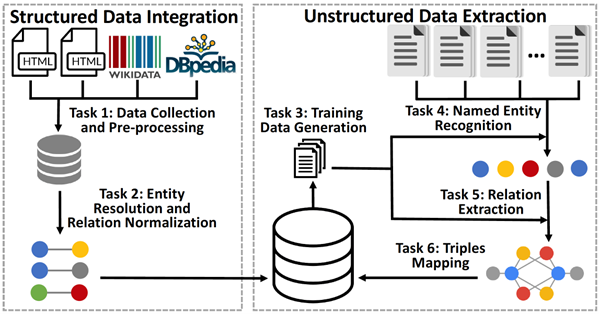
By collaborating with Huawei, Prof. Chen’s team utilize a big graph data corpus, i.e., Wikipedia to help the company improve the effectiveness of their searching application, Question-Answering system. One such research, HLP, pre-trains the dense retriever with the text relevance induced by hyperlink-based topology within Web documents. By injecting the knowledge of hyperlink-based structures in pre-training, the proposed method can provide effective relevance signals for large-scale pre-training and better facilitate downstream passage retrieval. Another research, Triple-fact Retriever aims to effectively retrieve a related document path in an explainable way for each question. The proposed system extracts a structured representation from the unstructured document and utilizes the knowledge of pre-trained language model (PLM) to do the semantic-level matching between the question and document.
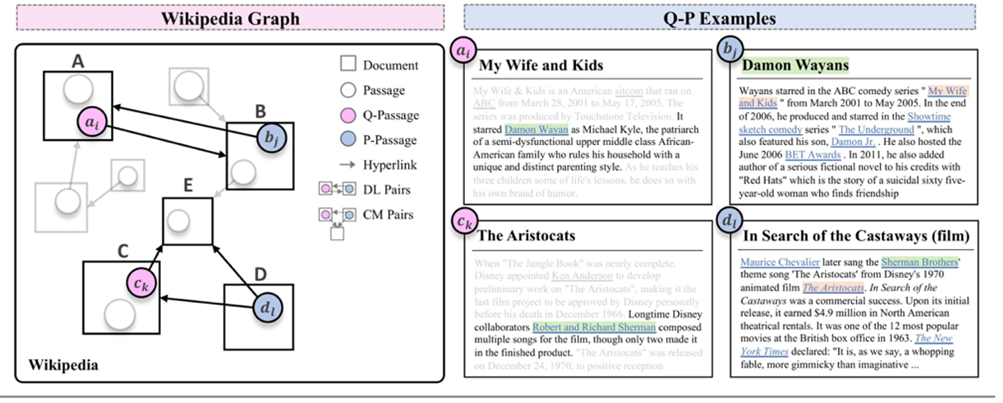
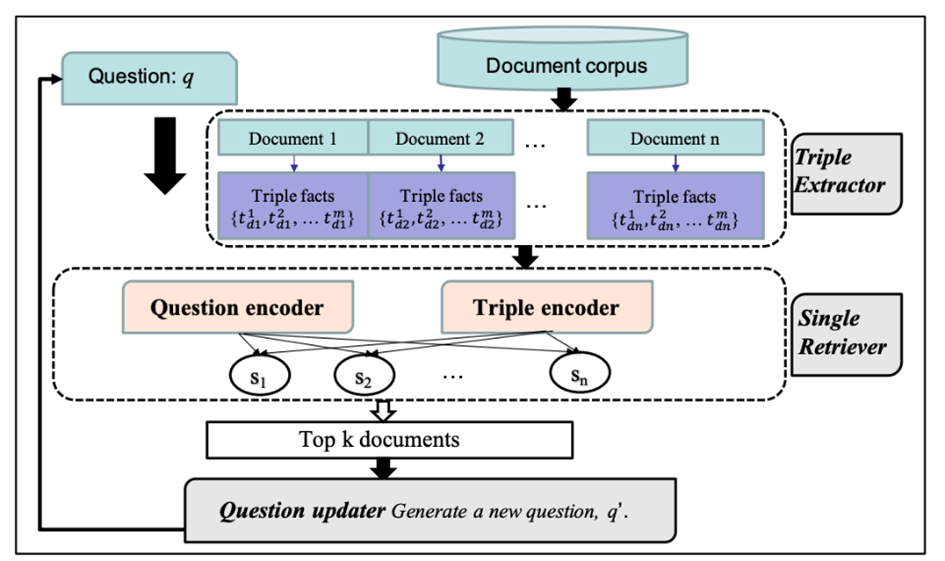
Prof. Chen’s team has helped Huawei to design an effective QA system, by an advanced pre-training model and a novel structure-aware document retriever model. Moreover, these approaches can help other web applications, such as web searching.
Project members

Publications
1. KartGPS: Knowledge Base Update with Temporal Graph Pattern-based Semantic Rules. Hao Xin, Lei Chen. ICDE 2024.
2. Cross-domain-aware Worker Selection with Training for Crowdsourced Annotation. Yushi Sun, Jiachuan Wang, Peng Cheng, Libin Zheng, Lei Chen, Jian Yin. ICDE 2024.
3. KGLink: A column type annotation method that combines knowledge graph and pre-trained language model. Yubo Wang, Hao Xin, Lei Chen. ICDE 2024.
4. Retrieval-based Disentangled Representation Learning with Natural Language Supervision. Jiawei Zhou, Xiaoguang Li, Lifeng Shang, Xin Jiang, Qun Liu,Lei Chen. ICLR 2024.
5. AIR: Adaptive Incremental Embedding Updating for Dynamic Knowledge Graphs. Zhifeng Jia, Haoyang Li, Lei Chen. DASFAA (2) 2023: 606-621
6. RECA: Related Tables Enhanced Column Semantic Type Annotation Framework. Yushi Sun, Hao Xin, Lei Chen. Proc. VLDB Endow. 16(6): 1319-1331 (2023)
7. Triple-Fact Retriever: An explainable reasoning retrieval model for multi-hop QA problem. Chengmin Wu, Enrui Hu, Ke Zhan, Lan Luo, Xinyu Zhang, Hao Jiang, Qirui Wang, Zhao Cao, Fan Yu, Lei Chen. ICDE 2022: 1206-1218.
8. CaSIE: Canonicalize and Informative Selection of the OpenIE system. Hao Xin, Xueling Lin, and Lei Chen. ICDE 2021: 2009-2014.
9. Fine-Grained Entity Typing via Label Noise Reduction and Data Augmentation. Haoyang Li, Xueling Lin, and Lei Chen. DASFAA (1) 2021: 356-374.
10. TENET: Joint Entity and Relation Linking with Coherence Relaxation. Xueling Lin, Lei Chen, and Chaorui Zhang. In Proceedings of the 2018 International Conference on Management of Data (SIGMOD), pp. 1142-1155. ACM, 2021.
11. KBPearl: a Knowledge Base Population System Supported by Joint Entity and Relation Linking. Xueling Lin, Haoyang Li, Hao Xin, Zijian Li, and Lei Chen. Proceedings of the VLDB Endowment 13, no. 7 (2020): 1035-1049.
12. AutoSF: Searching Scoring Functions for Knowledge Graph Embedding. Yongqi Zhang, Quanming Yao, Wenyuan Dai, and Lei Chen. In 2020 IEEE 36th International Conference on Data Engineering (ICDE).
13. Nscaching: Simple and Efficient Negative Sampling for Knowledge Graph Embedding. Yongqi Zhang, Quanming Yao, Yingxia Shao, and Lei Chen. In 2019 IEEE 35th International Conference on Data Engineering (ICDE), pp. 614-625. IEEE, 2019.
14. Canonicalization of Open Knowledge Bases with Side Information from Source Text. Xueling Lin, and Lei Chen. In 2019 IEEE 35th International Conference on Data Engineering (ICDE), pp. 950-961. IEEE, 2019.
15. Subjective Knowledge Base Construction Powered By Crowdsourcing and Knowledge Base. Hao Xin, Rui Meng, and Lei Chen. In Proceedings of the 2018 International Conference on Management of Data (SIGMOD), pp. 1349-1361. ACM, 2018.
16. Domain-Aware Multi-Truth Discovery from Conflicting Sources. Xueling Lin, and Lei Chen. Proceedings of the VLDB Endowment 11, no. 5 (2018): 635-647.
17. Knowledge Base Enhancement via Data Facts and Crowdsourcing. Linnan Jiang, Lei Chen, and Zhao Chen. In 2018 IEEE 34th International Conference on Data Engineering (ICDE), pp. 1109-1119. IEEE, 2018.
18. Knowledge Base Semantic Integration using Crowdsourcing. Rui Meng, Lei Chen, Yongxin Tong, and Chen Zhang. IEEE Transactions on Knowledge and Data Engineering (TKDE), 29(5):1087-1110, 2017.
19. CrowdFusion: A Crowdsourced Approach on Data Fusion Refinement. Yunfan Chen, Jason Chen Zhang, and Lei Chen. IEEE International Conference on Data Engineering (ICDE), San Diego, CA, USA, April 19-22, 2017.
20. CrowdTC: CrowdSourced Taxonomy Construction. Rui Meng, Yongxin Tong, Lei Chen, and Caleb Chen Cao. IEEE International Conference on Data Mining (ICDM), Atlantic City, NJ, USA, Nov 2015.
Project Period
2015-Present
Research Area
Sector-Specific Data Analytics