Orca: A Few-shot Benchmark for Chinese Conversational Machine Reading Comprehension
Abstract
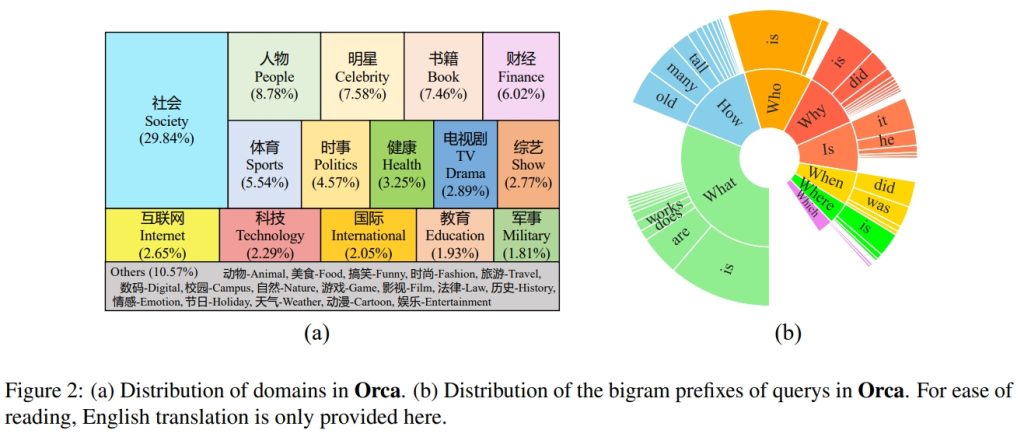
The conversational machine reading comprehension (CMRC) task aims to answer questions in conversations, which has been a hot research topic in recent years because of its wide applications. However, existing CMRC benchmarks in which each conversation is assigned a static passage are inconsistent with real scenarios. Thus, model's comprehension ability towards real scenarios are hard to evaluate reasonably. To this end, we propose the first Chinese CMRC benchmark \textbf{Orca} and further provide zero-shot/few-shot settings to evaluate model's generalization ability towards diverse domains. We collect 831 hot-topic driven conversations with 4,742 turns in total. Each turn of a conversation is assigned with a response-related passage, aiming to evaluate model's comprehension ability more reasonably. The topics of conversations are collected from social media platform and cover 33 domains, trying to be consistent with real scenarios. Importantly, answers in Orca are all well-annotated natural responses rather than the specific spans or short phrase in previous datasets. Besides, we implement three strong baselines to tackle the challenge in Orca. The results indicate the great challenge of our CMRC benchmark.

Project members

Jia LI
Assistant Professor
Publications
Orca: A Few-shot Benchmark for Chinese Conversational Machine Reading Comprehension. Nuo Chen, Hongguang Li, Junqing He, Yinan Bao, Xinshi Lin, Qi Yang, Jianfeng Liu, Ruyi Gan, Jiaxing Zhang, Baoyuan Wang, and Jia Li.
Project Period
2023
Research Area
Data-driven AI
Keywords
Conversational Machine Reading Comprehension, Dataset