Natural Response Generation for Chinese Reading Comprehension
Abstract
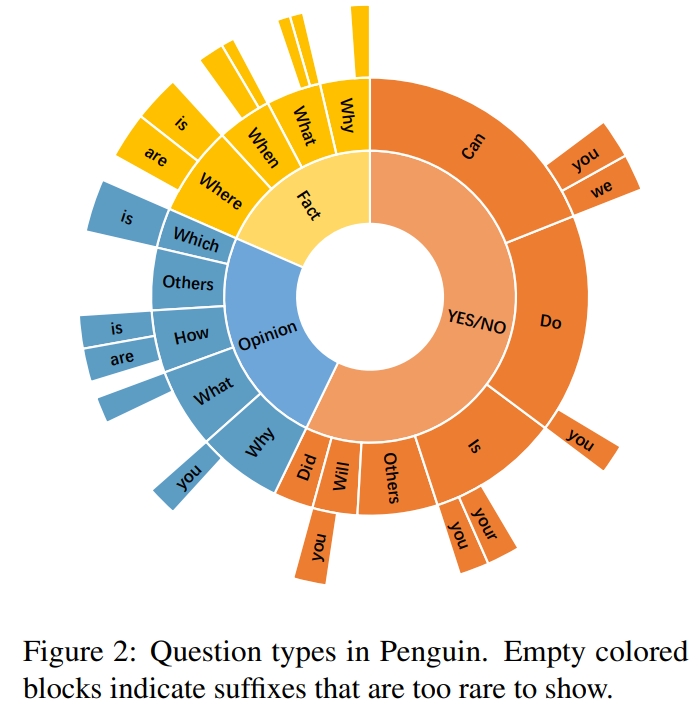
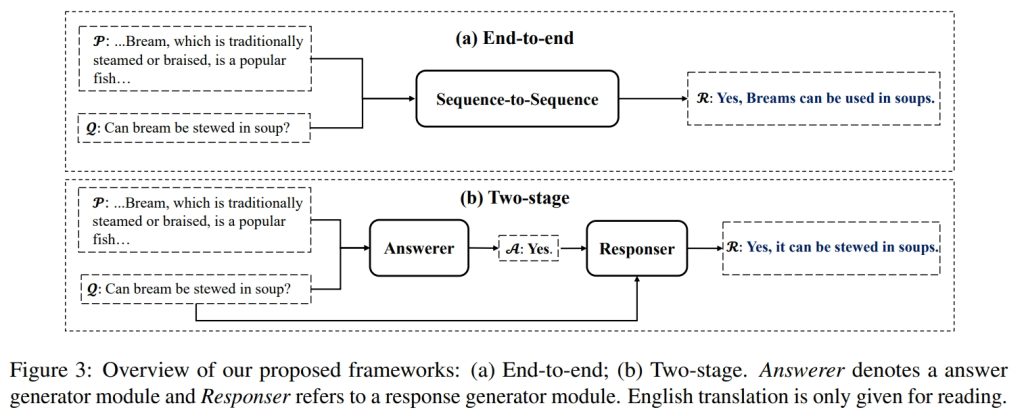
Machine reading comprehension (MRC) is an important area of conversation agents and draws a lot of attention. However, there is a notable limitation to current MRC benchmarks: The labeled answers are mostly either spans extracted from the target corpus or the choices of the given candidates, ignoring the natural aspect of high-quality responses. As a result, MRC models trained on these datasets can not generate human-like responses in real QA scenarios. To this end, we construct a new dataset called \textbf{Penguin} to promote the research of MRC, providing a training and test bed for natural response generation to real scenarios. Concretely, Penguin consists of 200k training data with high-quality fluent, and well-informed responses. Penguin is the first benchmark towards natural response generation in Chinese MRC on a relatively large scale. To address the challenges in Penguin, we develop two strong baselines: end-to-end and two-stage frameworks. Following that, we further design \textit{Prompt-BART}: fine-tuning the pre-trained generative language models with a mixture of prefix prompts in Penguin. Extensive experiments validated the effectiveness of this design.
Project members

Jia LI
Assistant Professor
Publications
Natural Response Generation for Chinese Reading Comprehension. Nuo Chen, Hongguang Li, Yinan Bao, Baoyuan Wang, and Jia Li.
Project Period
2023
Research Area
Data-driven AI
Keywords
Dataset, Machine Reading Comprehension