Demystifying Artificial Intelligence for Data Preparation
Abstract
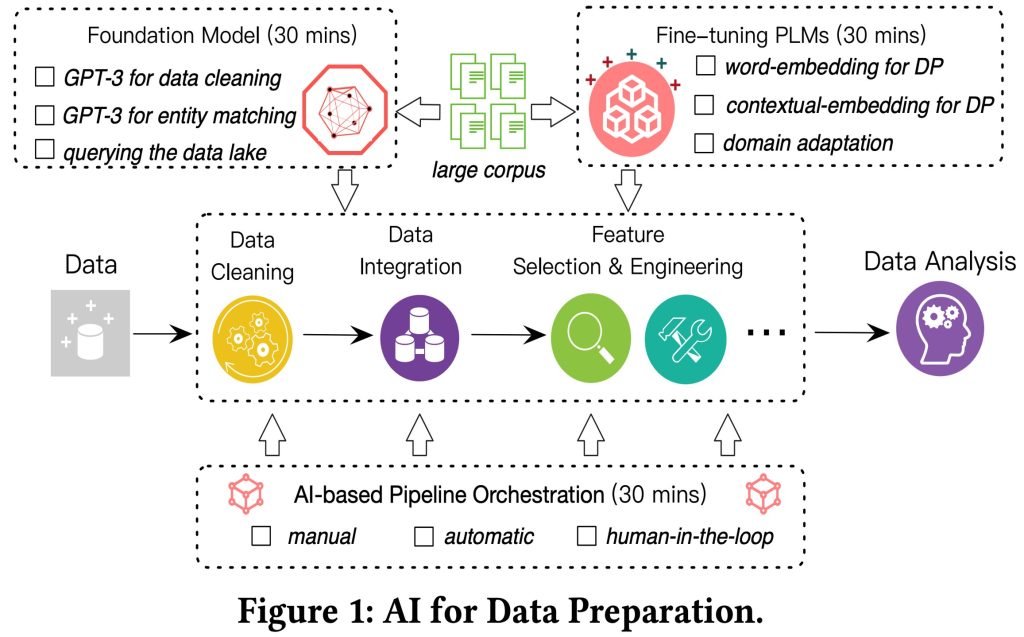
Data preparation – the process of discovering, integrating, transforming, cleaning, and annotating data – is one of the oldest, hardest, yet inevitable data management problems. Unfortunately, data preparation is known to be iterative, requires high human cost, and is error-prone. Recent advances in artificial intelligence (AI) have shown very promising results on many data preparation tasks. At a high level, AI for data preparation (AI4DP) should have the following abilities. First, the AI model should capture real-world knowledge so as to solve various tasks. Second, it is important to easily adapt to new datasets/tasks. Third, data preparation is a complicated pipeline with many operations, which results in a large number of candidates to select the optimum, and thus it is crucial to effectively and efficiently explore the large space of possible pipelines. In this tutorial, we will cover three important topics to address the above issues: demystifying foundation models to inject knowledge for data preparation, tuning and adapting pre-trained language models for data preparation, and orchestrating data preparation pipelines for different downstream applications.
Project members

Nan TANG
Associate Professor
Publications
Demystifying Artificial Intelligence for Data Preparation. Chengliang Chai, Nan Tang, Ju Fan, and Yuyu Luo. SIGMOD 2023 Tutorial.
Project Period
2023
Research Area
Data-driven AI & Machine Learning
Keywords
artificial intelligence, data preparation, foundation models