Data Matching
Abstract
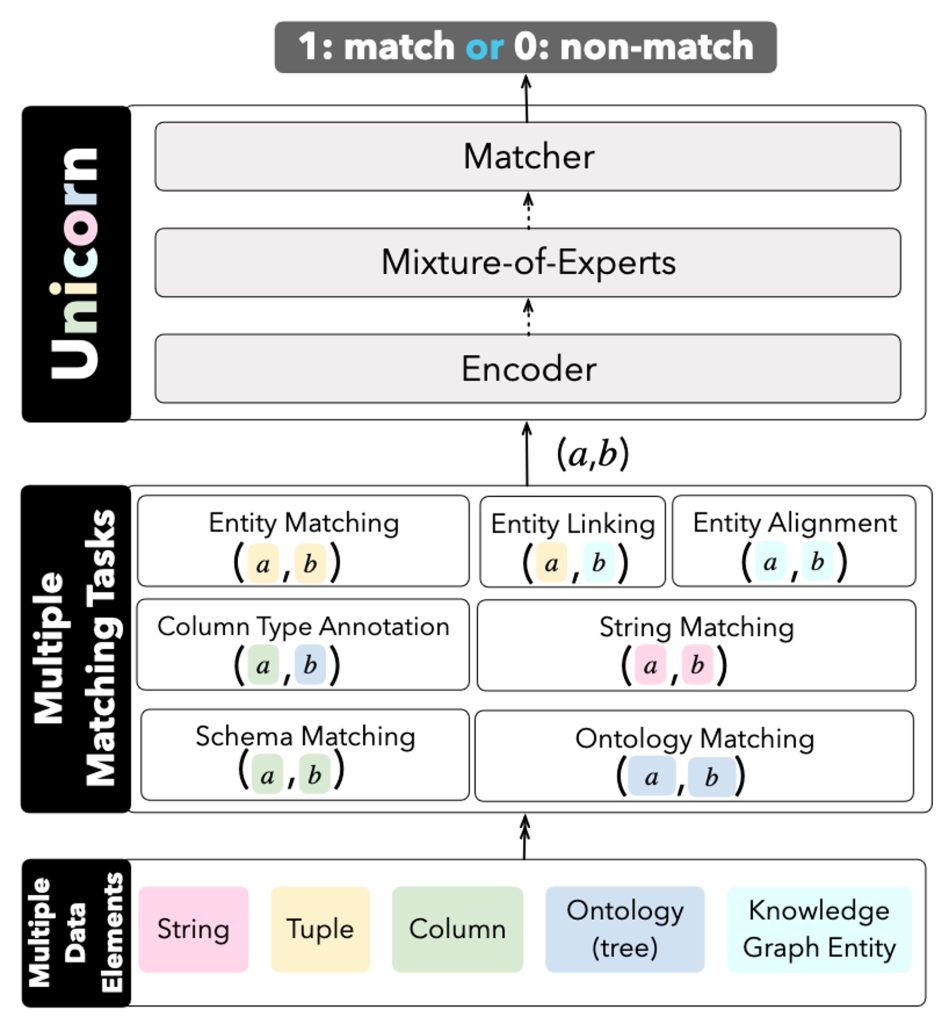
Data matching generally refers to the process of deciding whether two data elements are the “same” (a.k.a. a match) or not, where each data element could be of different classes such as string, tuple, column, and so on. Data matching is a key concept in data integration and data preparation that includes a wide spectrum of tasks. In this paper, we consider seven common data matching tasks, namely entity matching, entity linking, entity alignment, string matching, column type annotation, schema matching, and ontology matching.
Project members

Nan TANG
Associate Professor
Publications
1. Unicorn: A Unified Multi-tasking Model for Supporting Matching Tasks in Data Integration. Jianhong Tu, Ju Fan, Nan Tang, Peng Wang, Guoliang Li, Xiaoyong Du, Xiaofeng Jia, and Song Gao.
2. DADER: Hands-Off Entity Resolution with Domain Adaptation. Jianhong Tu, Xiaoyue Han, Ju Fan, Nan Tang, Chengliang Chai, Guoliang Li, and Xiaoyong Du.
3. Domain Adaptation for Deep Entity Resolution. Jianhong Tu, Ju Fan, Nan Tang, Peng Wang, Chengliang Chai, Guoliang Li, Ruixue Fan, and Xiaoyong Du.
4. Deep Learning for Blocking in Entity Matching: A Design Space Exploration. Saravanan Thirumuruganathan, Han Li, Nan Tang, Mourad Ouzzani, Yash Govind, Derek Paulsen, Glenn Fung, and AnHai Doan.
5. Distributed Representations of Tuples for Entity Resolution. Muhammad Ebraheem, Saravanan Thirumuruganathan, Shafiq Joty, Mourad Ouzzani, and Nan Tang.
6. Synthesizing Entity Matching Rules by Examples. Rohit Singh, Venkata Vamsikrishna Meduri, Ahmed Elmagarmid, Samuel Madden, Paolo Papotti, Jorge-Arnulfo Quiané-Ruiz, Armando Solar-Lezama, and Nan Tang.
7. Generating Concise Entity Matching Rules. Rohit Singh, Vamsi Meduri, Ahmed Elmagarmid, Samuel Madden, Paolo Papotti, Jorge-Arnulfo Quiané-Ruiz, Armando Solar-Lezama, and Nan Tang.
Project Period
2022-Present
Research Area
AI for DB
Keywords
AI, matching