Quantifying and Mitigating Privacy Risks of Contrastive Learning
Abstract
Data is the key factor to drive the development of machine learning (ML) during the past decade. However, high-quality data, in particular labeled data, is often hard and expensive to collect. To leverage large-scale unlabeled data, self-supervised learning, represented by contrastive learning, is introduced. The objective of contrastive learning is to map different views derived from a training sample (e.g., through data augmentation) closer in their representation space, while different views derived from different samples more distant. In this way, a contrastive model learns to generate informative representations for data samples, which are then used to perform downstream ML tasks. Recent research has shown that machine learning models are vulnerable to various privacy attacks. However, most of the current efforts concentrate on models trained with supervised learning. Meanwhile, data samples' informative representations learned with contrastive learning may cause severe privacy risks as well.
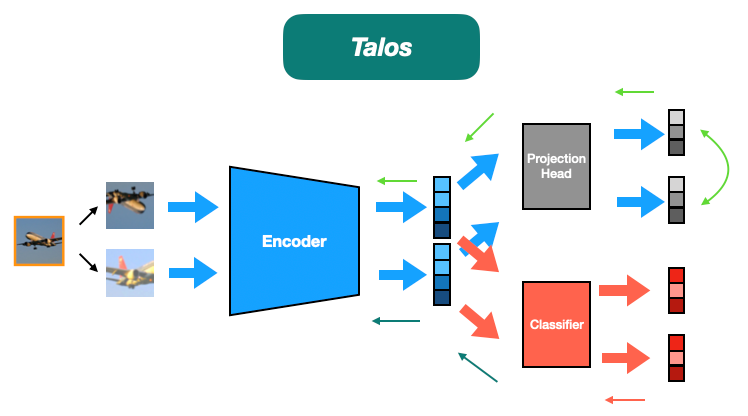
In this paper, we perform the first privacy analysis of contrastive learning through the lens of membership inference and attribute inference. Our experimental results show that contrastive models trained on image datasets are less vulnerable to membership inference attacks but more vulnerable to attribute inference attacks compared to supervised models. The former is due to the fact that contrastive models are less prone to overfitting, while the latter is caused by contrastive models' capability of representing data samples expressively. To remedy this situation, we propose the first privacy-preserving contrastive learning mechanism, Talos, relying on adversarial training. Empirical results show that Talos can successfully mitigate attribute inference risks for contrastive models while maintaining their membership privacy and model utility.
Project members

Xinlei HE
Assistant Professor
Publications
Quantifying and Mitigating Privacy Risks of Contrastive Learning. Xinlei He, and Yang Zhang.
Project Period
2021
Research Area
Data-driven AI & Machine Learning、Security and Privacy
Keywords
Attribute Inference Attack, Contrastive Learning, Membership Inference Attack